[For all those who read all my blogs, yes, I accidentally published this to the wrong one yesterday. Whoops.]
Yes, more geek-fu for you today, but it’s useful geek-fu, simple, and cross-platform. Requires Lynx, Python, and a script I’ll point out. All free.
I have tons of saved web pages. Sometimes they’re reference, sometimes they’re just saved blog pages. But there’s few viewers that simply give me the text quickly and simply.
Enter lynx – a text-based browser. ( Main | OSX | Windows ) It’s fast and simple, and can browse your local directory pretty easily. (Arrow keys follow links and go back – you’ll get used to it pretty quickly.)
You edit LYNX.CFG – and the one line that starts with STARTFILE you change to this:
STARTFILE:file://localhost/~/
Or if you don’t even want to do that, type “G” in Lynx, and then paste:
file://localhost/~/
The problem is that the layout is … um, informative but unusable. (I *like* the colors, you can set your own.)

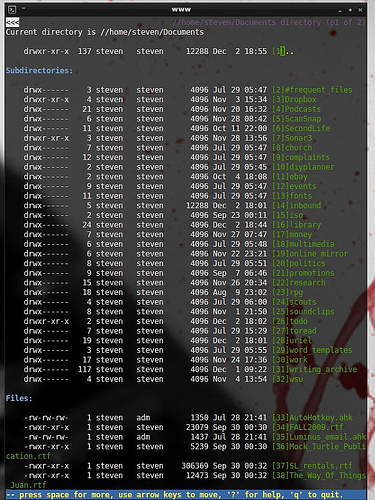
Looks like dog doo. I much prefer this:

So, you’ve got Python already, yes? Now you can download DropboxIndex. It’s a useful script in its own right if you have dropbox, but it also makes a dead simple directory tree.
Unpack the files into their own directory. Copy template-example.html to template.html. You use Dropbox index like this on all systems (from the command line):
*nix
python dropbox-index.py -R -T template.html ~/Documents
Win32 (not sure if you have to use short filenames)
python dropbox-index.py -R -T template.html C:/MyDocu~1
The examples have it indexing your entire “my documents” directory. This WILL place an INDEX.HTML file in each directory – so don’t just throw it at your entire hard drive!
Then you point lynx at the index.html file…
file://localhost/~/Documents/index.html
The results look a lot better in lynx, so you can easily move around your directories and view the files (lynx should call viewers for things it can’t handle). And because it’s just sitting at the command line, it takes up next to no resources, so you can keep it open all the time.
Geek-fu!